 A few years ago, I had the pleasure of joining an art project conceived by Melanie McLain. She enlisted programmer and math super-genius Kree Cole-McLaughlin to begin the programming side of an idea to write a piece of software that could read text and turn it into music.
A few years ago, I had the pleasure of joining an art project conceived by Melanie McLain. She enlisted programmer and math super-genius Kree Cole-McLaughlin to begin the programming side of an idea to write a piece of software that could read text and turn it into music.
Her previous examinations into speech and writing led her naturally to this point, and getting into the software and composition stages brought the opportunity to pull in a few more horses with Kree and myself. Kree had already laid the foundation for the hard part of properly parsing and organizing the text in as many meaningful and useful ways as possible. I was added to the project to take the data Kree had parsed and find ways to make it musically significant with some generative music programming in Max/MSP. All along the way, Melanie was always lighting up with new ideas and ways to make things better, more interesting, or intuitive. There are many forms that this project, now dubbed “Sonic Prose”, may take in the future. Scraps of paper, late-night idea emails, and several dusty text files, all conjured at design meetings by the three of us, offer no shortage of possible performance setups.
For now, it might be good to let Sonic Prose at least start speaking to the world a bit, so here is a short video example of the program in its proof-of-concept state performing a basic reading. Details about how the software works below the video window.
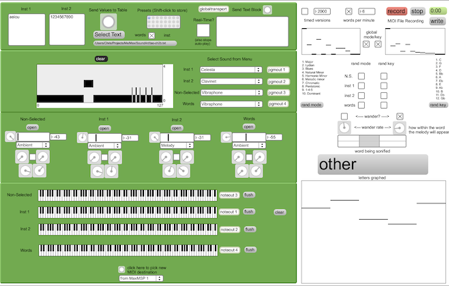
In this example, Sonic Prose is generating a stream of MIDI information that tells the computer what notes to play on which instruments. The words are split into their sounds in a few ways. In this simple example, the vowels are sent to one sound, all consonants are sent to another sound, and the whole word is used as the chord bed in the background. The word readout at the right of the screen will show you the word being sonified, and the graph below it is the melodic shape that word takes based on its letter positioning in the alphabet. This melody gets broken up between the vowel and consonant splitters, though you can often still decipher the phrase created between the two.
At the top right, probability tables are setup to run through potential key and mode changes. A high bar will occur more frequently, and a low bar less frequently. The actual percentages are based on the individual bar’s value as it relates to the sum of all present bars. The “wander” section in the middle-right determines when the melodic notes will be played in relation to the timing of the word. So, if the solid part starts at the halfway mark, the melody sounds will not begin to trigger until the word is half-way through playing. Word speed is determined in the top right as either milliseconds per letter (timed versions) or a words per minute. The milliseconds per letter provides a more steady rhythmic performance, while words per minute will have a more free rhythm because the melody parts will fit different numbers of notes into the same length of time.
If we take a look at the green section, the keyboards at the bottom will show you what notes are actually being performed by the different instrument groups. In the example I’m providing, the MIDI is being sent to an outside sound source, so the instrument selections are not active. The black and white graph is showing the assignment of all the ascii values to either instrument 1 (vowels), instrument 2 (numbers), and the leftovers. The knobs under each instrument group provide the user with control over certain aspects like track volume, random variations, performance mode, and transposition. The kinds of questions that this project raises might include:
- What might we hear in the emotional quality of the music that informs some aspect of the written text?
- What kinds of mapping techniques of alphabet/pitch might yield more dramatic results?
- How could word quality or definition be incorporated into the piece, such that darker words yield darker tones, or could etymology be factored in more directly?
- Are there any practical data-sonification applications for this simple approach?